Inside My Algorithmic Trading Infrastructure
I trade Indian equities and crypto using reinforcement learning bots that run 24/7. The whole thing runs on three machines - a cloud server, a home GPU box, and my laptop. No Kubernetes, no fancy orchestration, no cloud ML platforms. Just systemd, cron, SSH, and a lot of shell scripts.
This post is the full picture: what each machine does, how data flows, how models get trained daily, and how everything stays alive without me touching it.
The Three Machines
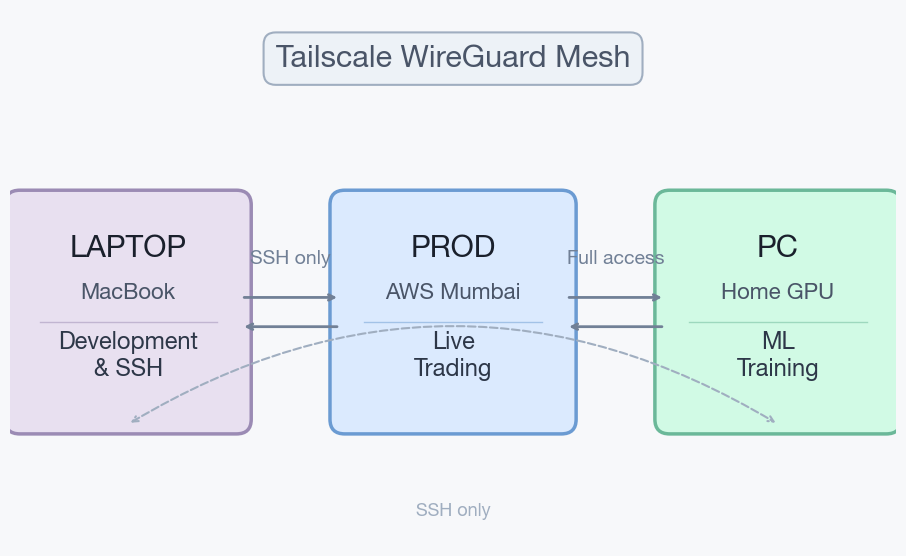
- PROD is an AWS instance in Mumbai. Small box - 2 vCPU, 4 GB RAM, 38 GB disk. Runs every live service: trading bots, data collectors, dashboards, notifications, monitoring. This is the machine where real money moves.
- PC is a home GPU box in Delhi. RTX 3080 with 10 GB VRAM, 24 CPU cores, 16 GB RAM, and almost a terabyte of NVMe storage. Its only job is training ML models and storing backups.
- Laptop is my MacBook. Development only - writing code, SSH into servers, monitoring dashboards.
All three machines are connected via a Tailscale WireGuard mesh. The laptop can only reach SSH ports on the servers. PROD and PC have full connectivity because they need to sync data, transfer models, and run database operations constantly.
The cloud server's public SSH port is completely closed. The only way in is through the encrypted Tailscale tunnel. More on the security setup in my other post.
What Runs on PROD
PROD is the nerve center. Eight systemd services run continuously, auto-restarting on failure:
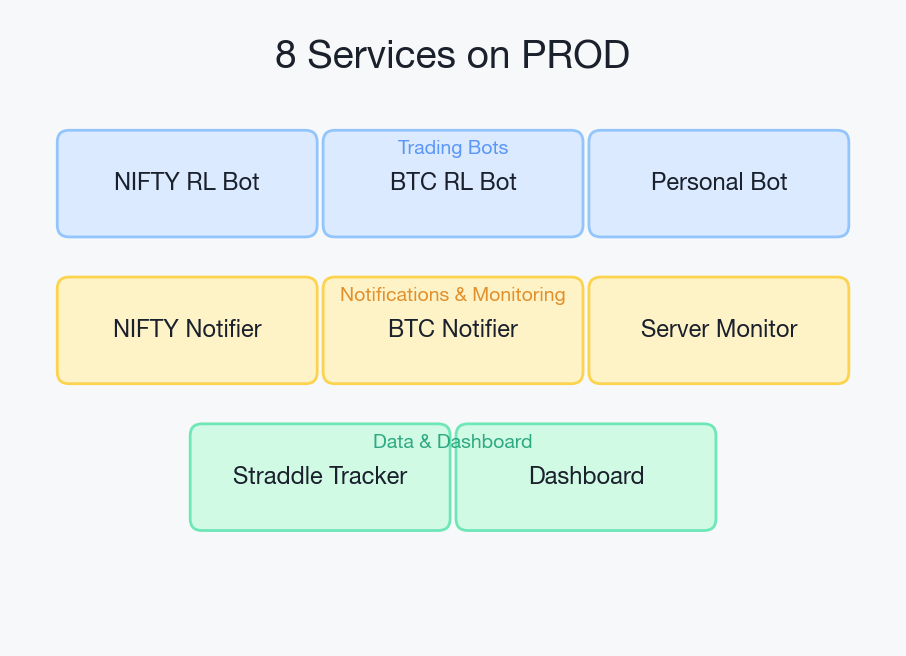
- NIFTY RL Bot - Reinforcement learning bot trading NIFTY futures across three timeframes (15-minute, 1-hour, and daily). Uses a Temporal Fusion Transformer policy.
- BTC RL Bot - Same architecture, trading BTC/USDC perpetuals on a crypto exchange. Two timeframes (1-hour and 4-hour).
- Personal Pattern Bot - Learns my manual trading patterns via behavioral cloning, then fine-tunes with RL. Generates daily "what to trade tomorrow" signals.
- NIFTY Notifier - Sends PnL updates to Telegram every 15 minutes during market hours.
- BTC Notifier - Same for the crypto bot, running 24/7.
- Straddle Tracker - Tracks ATM straddle/strangle prices via broker WebSocket during market hours. Controlled by a scheduler that starts/stops it based on Indian market hours and NSE holidays.
- Dashboard - FastAPI backend serving a web dashboard with positions, PnL charts, and trade history. Sits behind nginx.
- Server Monitor - Reports CPU, RAM, and disk stats to Telegram every 15 minutes.
Each service has its own Python virtual environment and log files. If any service crashes, systemd restarts it automatically within seconds.
The Databases
Five PostgreSQL databases live on PROD, totaling about 350 MB:
| Database | Size | What's Inside |
|---|---|---|
| NIFTY Trading | ~77 MB | Market data, features, trades, positions, PnL snapshots |
| BTC Trading | ~64 MB | Same structure for crypto markets |
| Straddle | ~42 MB | ATM straddle price snapshots (every tick during market hours) |
| Options | ~154 MB | Per-minute quotes for ~730 instruments (NIFTY/SENSEX/BANKNIFTY options) |
| Allocator | ~8 MB | Monthly asset allocation metrics across equity, crypto, and commodities |
The options database uses partitioned tables because it ingests ~730 data points every single minute during market hours. That's about 350,000 rows per trading day.
The Daily Timeline
A typical weekday looks like this:
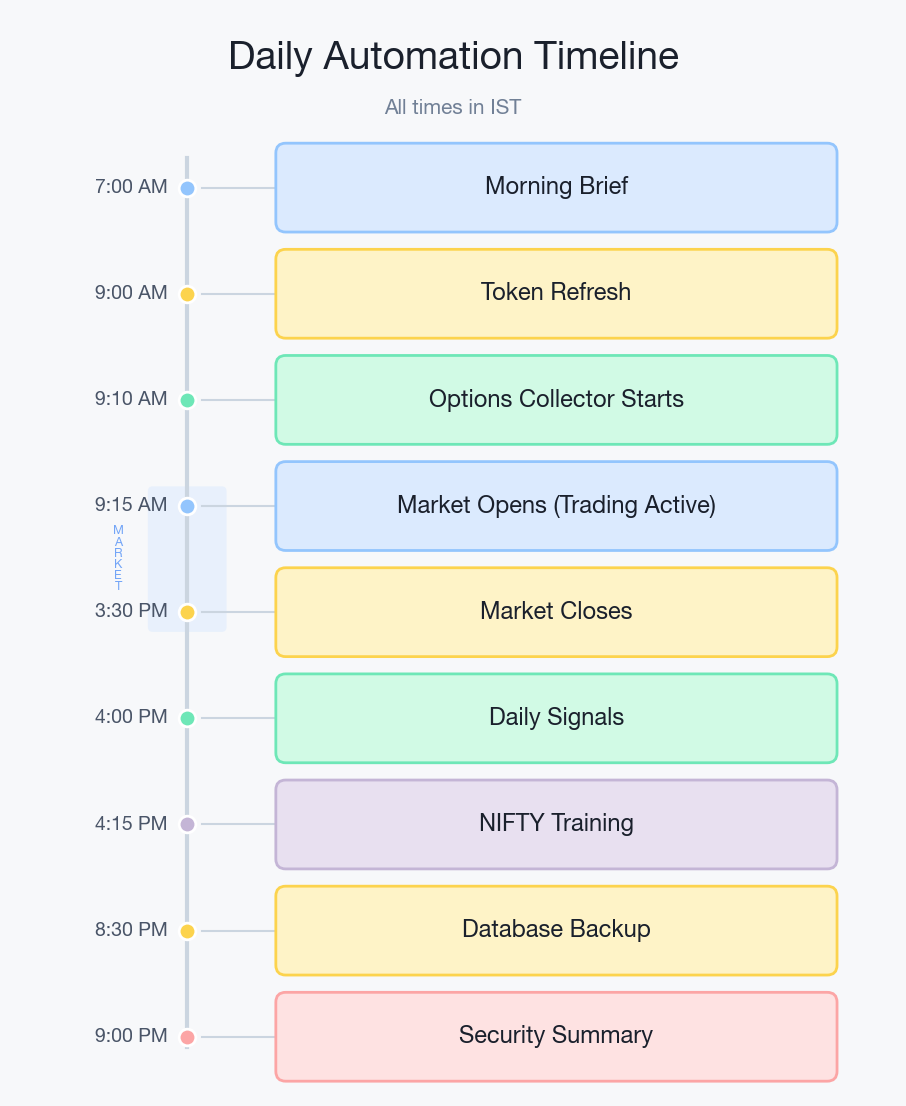
- 7:00 AM - A morning briefing script generates a PDF with market overview, crypto prices, and news. Sent via Telegram.
- 9:00 AM - Broker API token refreshes automatically via headless login.
- 9:10 AM - Options data collector starts. Polls ~730 instruments every minute until market close.
- 9:15 AM - Market opens. Straddle tracker starts via the scheduler. Trade fetcher begins polling my manual trades. The NIFTY bot is already running and starts actively checking for signals.
- 9:15 AM - 3:30 PM - Active trading hours. Bots execute trades, notifiers send PnL updates every 15 minutes, server monitor reports system health. The BTC bot trades independently 24/7 on its own schedule.
- 3:30 PM - Market closes. Straddle tracker and options collector shut down automatically.
- 4:00 PM - Personal bot generates daily signals for the next trading day.
- 4:05 PM - End-of-day PnL chart saved.
- 4:15 PM - NIFTY training kicks off (data syncs to the GPU box, trains, models sync back).
- 8:30 PM - Database backups dump to the GPU box.
- 9:00 PM - Security monitoring daily summary via Telegram.
The BTC bot trains every 2 hours, 24/7. It's on a separate schedule because crypto markets never close.
The Training Pipeline
This is probably the most interesting part of the setup. Every day, the bots retrain themselves on the latest market data.

The flow is the same for all bots:
Step 1: Data Export. PROD dumps the latest market data and computed features from PostgreSQL into a compressed file.
Step 2: Ship to PC. The dump file is transferred to the GPU box via SCP over the Tailscale mesh.
Step 3: Import & Train. The GPU box imports the data into its local PostgreSQL, then runs the training script. The Temporal Fusion Transformer trains on the RTX 3080 with CUDA - typically 50,000 to 100,000 timesteps per run. This takes 10-30 minutes depending on the timeframe.
Step 4: Integrity Check. After training, SHA256 checksums are computed for every model file on the GPU box.
Step 5: Ship Models Back. The trained model files are rsynced back to PROD. Checksums are verified on arrival. If any file is corrupted during transfer - Telegram alert fires, the previous model is kept, and the new one is rejected. A bad model file won't crash the bot - it'll just make bad trades silently. The checksum catches this.
Step 6: Archive. The model is archived on the GPU box with a timestamp. The last 30 training runs are kept, so I can roll back to any previous model if the new one performs poorly in live trading.
Step 7: Cleanup. Old model files on PROD are cleaned up (only the latest 2 per timeframe are kept), and the updated models are pushed to GitHub.
The whole pipeline is orchestrated by a single shell script triggered by cron. NIFTY trains daily at 4:15 PM after market close. BTC trains every 2 hours. Each run is idempotent - if training already completed today, the script skips.
The Backup Strategy
PROD has only 38 GB of disk, 80% full. If that disk dies, everything is gone - years of market data, trained models, trade history. So the GPU box (with 800+ GB free) serves as the backup target.
Database backups run nightly at 8:30 PM. Each of the 4 trading databases gets dumped in compressed format (~40 MB total), rsynced to the GPU box, and a Telegram notification confirms success. Retention: 7 daily snapshots, plus 4 weekly (Sundays), plus 3 monthly (1st of month). I can restore any database to any of those points.
Model backups happen automatically during each training run. Before old models get cleaned up, they're archived with timestamps on the GPU box. 30 archives per bot. If a new model starts losing money, rollback is one SCP command away.
Model integrity is verified via SHA256 checksums after every transfer. A corrupted .zip model file looks fine to the filesystem but produces garbage predictions. The checksum catches it before the bot ever loads it.
What the Bot Architecture Looks Like
All three bots (NIFTY, BTC, and the personal one) share the same core architecture:
- Policy Network: Temporal Fusion Transformer (TFT) - a Google architecture designed for multi-horizon time-series forecasting. Also supports MLP and LSTM as alternatives.
- Action Space: 7 discrete actions - strong buy, buy, weak buy, hold, weak sell, sell, strong sell. This gives the bot nuance beyond just "buy/sell/hold."
- Training: Reinforcement learning with PPO (Proximal Policy Optimization). The reward function accounts for PnL, risk-adjusted returns, and drawdown penalties.
- Feature Engineering: Technical indicators (RSI, EMA, Bollinger Bands, ATR, etc.) computed at each timeframe, plus cross-timeframe features.
The NIFTY bot trains on NIFTY spot (index) data but executes on futures. The BTC bot trades perpetual futures on a crypto exchange. The personal bot uses behavioral cloning on my manual trades first, then fine-tunes with RL - so it's learning my trading style, not just optimizing for returns.
The Monitoring Stack
I don't have Grafana or Prometheus. Everything goes through Telegram.
Four separate Telegram bots handle different concerns:
- Trading notifications - PnL updates, trade executions, position changes
- Infrastructure - Server health, security alerts, backup confirmations, model integrity
- Options data - Collection status and errors (separate to avoid noise in the main chat)
- Morning brief - Daily market overview PDF
A security monitoring script runs every 15 minutes checking: failed SSH attempts, disk usage (warn at 85%, critical at 90%), all systemd services running, and new fail2ban bans. A daily summary at 9 PM gives the full picture.
If a service goes down at 3 AM, I get a Telegram notification within 15 minutes. If someone tries to brute-force SSH (which they can't, since the port is closed - but the monitor checks anyway), I know about it.
Why This Architecture
A few conscious decisions:
Why not cloud ML (SageMaker, Vertex AI, etc.)? Cost. The GPU box cost about 800 USD one-time. Training runs ~30 minutes per day. A comparable cloud GPU instance running daily would cost 100+ USD/month. The box pays for itself in 8 months.
Why not Docker/Kubernetes? Overkill. I have 8 services on one server. Systemd handles restarts, logging, and dependency management. Adding container orchestration would add complexity without benefit at this scale.
Why PostgreSQL for market data? Because the bots need to query historical data with complex filters (date ranges, feature calculations, joins). A flat-file approach would require loading everything into memory. PostgreSQL handles the heavy lifting with indexes.
Why Tailscale? It turns three machines in different locations into a single secure network with zero port forwarding, zero firewall configuration, and zero certificates to manage. Setup took 10 minutes. WireGuard encryption handles the rest.
Why retrain daily? Markets are non-stationary. A model trained on last month's data might not work this month. Daily retraining on the freshest data keeps the bot adapted. The 30-archive rollback is the safety net.
The Numbers
- Services running 24/7: 8
- Cron jobs: 13
- Databases: 5 (total ~350 MB)
- Daily data ingestion: ~350,000 options quotes + continuous market data
- Training frequency: NIFTY daily, BTC every 2 hours
- Backup retention: 7 daily + 4 weekly + 3 monthly database snapshots, 30 model archives per bot
- Monthly cost: ~15 USD for the AWS instance + ~5 USD for Mullvad VPN. GPU box was a one-time cost.
- Time to recover from disk failure: ~30 minutes (restore from last night's backup on PC)
Lessons Learned
1. Systemd is underrated. Most people reach for Docker or PM2. Systemd comes pre-installed, handles auto-restart, logging (journalctl), dependencies, and resource limits. For single-server deployments, it's all you need.
2. Always verify model integrity after transfer. I learned this after a rsync transfer silently corrupted a model file. The bot didn't crash - it just started making weird trades. SHA256 checksums after every transfer caught this class of bug permanently.
3. Separate your Telegram bots by concern. I initially had everything going through one bot. The noise was unbearable - 15-minute PnL updates mixed with backup confirmations mixed with security alerts. Four bots, one chat, different notification patterns.
4. The GPU box is the best investment. One-time cost, unlimited training. I've run thousands of training iterations. On cloud GPUs that would have cost a small fortune.
5. Never run deferred tasks from your laptop. If you need something to happen "when training finishes," push it to a server as a background process. Your laptop will sleep, your WiFi will drop, your terminal will close. The server won't.
6. Daily retraining with rollback > periodic retraining without rollback. The bot is always learning, but if it learns the wrong lesson, you can undo it in seconds. The 30-archive buffer has saved me twice.
This setup has been running continuously since late 2025. It's not perfect - PROD is running tight on disk, I'd like offsite backups beyond the GPU box, and the monitoring could use a proper dashboard instead of just Telegram. But it works, it's simple enough to debug at 2 AM, and the total cost is under 20 USD/month.
The best infrastructure is the one that runs without you thinking about it.