Temporal Fusion Transformers: The Architecture That's Changing Algorithmic Trading
The Problem With Traditional Models in Trading
Most retail algo traders follow a predictable path. They start with moving average crossovers, graduate to machine learning classifiers (random forests, XGBoost), maybe dabble in LSTMs, and then plateau. The models work okay in backtests but fall apart in live markets.
Why? Because financial markets have a unique structure that most ML architectures weren't designed for:
- Multiple time horizons matter simultaneously. A 15-minute scalp still needs to respect the daily trend. A 4-hour swing trade is affected by both the 1-hour momentum and the weekly structure.
- Not all features matter all the time. RSI is useful in ranging markets but worthless during a breakout. Volume spikes matter near support/resistance but are noise otherwise.
- Regime changes are abrupt. The model that prints money in a trending market gets destroyed in a choppy one. Markets don't send you a memo when the regime changes.
LSTMs handle the sequential nature of price data reasonably well. They maintain a memory cell that carries information forward, candle by candle. But they have a fundamental limitation -information decays over distance. An LSTM reading candle #500 has largely forgotten what happened at candle #1. It sees the market through a foggy rearview mirror.
Transformers, the architecture behind GPT, solve this with self-attention -every candle can directly look at every other candle regardless of distance. But vanilla transformers are data-hungry beasts. They need hundreds of thousands of samples to train properly. In crypto, where you might have 2-3 years of hourly data (~25,000 candles), that's a problem.
Enter the Temporal Fusion Transformer.
What Is a Temporal Fusion Transformer?
The Temporal Fusion Transformer (TFT) was introduced by Google in 2019. It was purpose-built for multi-horizon time-series forecasting -predicting not just the next value, but multiple steps ahead, while explaining why it made those predictions.
Think of it as an architecture that combines the best of three worlds:
1. LSTMs for local pattern recognition The TFT uses an LSTM encoder-decoder to capture short-term sequential dependencies. This is your bread and butter -momentum, mean reversion signals, recent volatility patterns. The LSTM processes the sequence and hands a compressed representation to the next layer.
2. Multi-head self-attention for long-range dependencies On top of the LSTM output, a transformer-style attention mechanism identifies which historical candles are most relevant to the current prediction. This is where TFT shines. It can learn that a support level tested 200 candles ago is relevant to today's price action -something a pure LSTM would struggle with.
3. Variable selection networks for automatic feature importance This is the killer feature. Before the data even hits the LSTM or attention layers, a gating mechanism learns which input features are useful at each timestep. In a trending market, it might upweight momentum indicators. In a ranging market, it might focus on mean-reversion signals. This happens automatically -no manual feature engineering required.
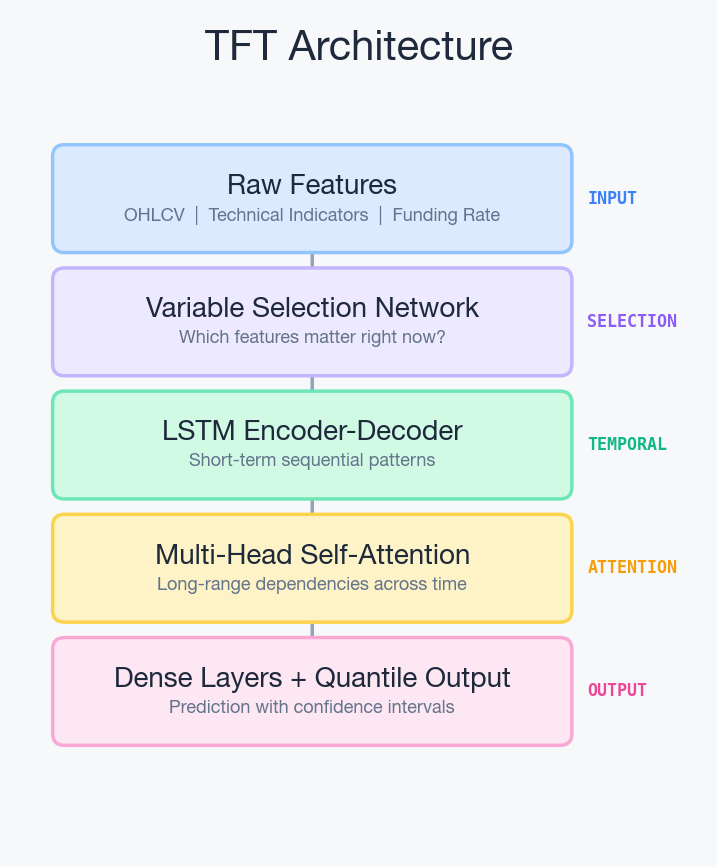
Why TFT Over a Pure LSTM or Pure Transformer?
I've been running RL-based trading bots with LSTM policies for a while now. They work. The 1-hour bot captures intraday momentum, the 4-hour bot catches swing moves. But there are clear limitations I keep hitting:
The LSTM forgets regime changes. If the market spent the last 3 weeks in a tight range and suddenly breaks out, the LSTM's memory of the last breakout (maybe 2 months ago) has faded. It takes several candles of the new regime before the LSTM adapts. Those first few candles are expensive.
Feature engineering is manual and static. I feed the model ~1000 features -technical indicators, volume profiles, various lookback windows. But which features matter changes over time. RSI divergence is gold in a range, noise in a trend. I can't manually switch feature sets based on market regime. The model needs to figure this out on its own.
No interpretability. When my LSTM bot takes a trade, I have no idea which features drove the decision. Was it the RSI oversold reading? The volume spike? The proximity to a support level? With TFT's attention weights and variable importance scores, you can literally visualize what the model is looking at.
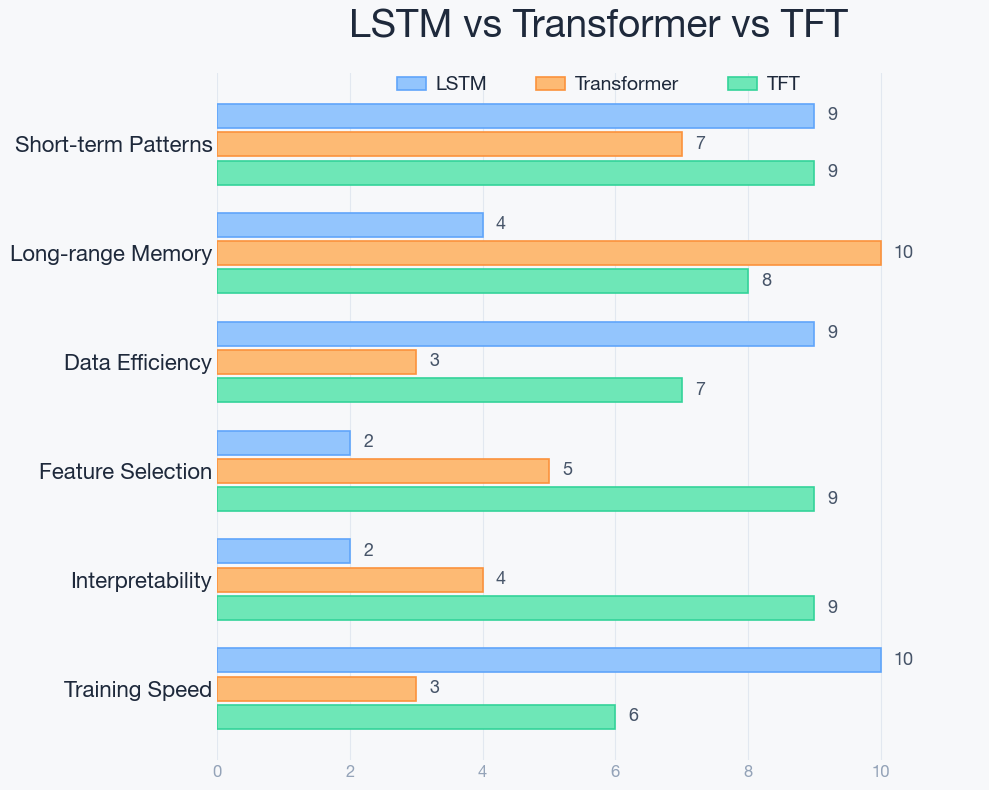
Here's a detailed comparison of what I've observed:
| Aspect | Pure LSTM | Pure Transformer | TFT |
|---|---|---|---|
| Data needed | 2k-10k samples | 50k+ samples | 15k-25k samples |
| Short-term patterns | Excellent | Good | Excellent |
| Long-range memory | Weak (decays ~200 steps) | Excellent | Strong (attention layer) |
| Feature selection | Manual | Learned but needs tons of data | Built-in gating |
| Interpretability | None | Attention maps (noisy) | Clean variable importance + temporal attention |
| Regime adaptation | Slow | Fast (if enough data) | Moderate to fast |
| Training on single GPU | Fast (minutes) | Slow (hours) | Moderate (30-60 min) |
The Data Question
The biggest constraint for any deep learning model in trading is data. Here's the reality:
- 1-hour candles, 3 years of history = ~26,000 samples. This is in TFT's sweet spot. Not enough for a vanilla transformer, more than enough for a well-configured TFT.
- 4-hour candles, 3 years = ~6,500 samples. Tighter, but TFT's LSTM backbone handles this better than a pure attention model would.
- Adding multiple assets multiplies your data. If you train on BTC, ETH, and SOL simultaneously, your effective dataset triples without needing more history.
The approach I'm exploring: train on maximum available history from multiple data sources, using TFT's variable selection to automatically handle the feature relevance problem.
You don't need to manually engineer "is this a trending or ranging market" features. The variable selection network figures it out from the raw indicators. You don't need to hand-tune lookback windows -the attention mechanism learns which historical distances are relevant.
How TFT Fits Into an RL Trading System
Most TFT examples you'll find online use it for pure forecasting -predict the next N candles of price movement. That's useful but incomplete. A forecast of "+2% in 4 hours" doesn't tell you how much to bet, when to exit, or how to manage risk.
The approach that interests me is using TFT as the feature extraction backbone inside a reinforcement learning agent:
- TFT processes the raw market data and outputs a rich, context-aware representation -essentially a compressed summary of "here's what matters in the current market state"
- The RL policy head (PPO, in my case) takes that representation and decides actions: buy, sell, hold, position size
- The reward signal comes from actual PnL, not prediction accuracy
This is fundamentally different from "predict price, then trade the prediction." The RL agent learns to trade, not to forecast. The TFT just gives it better eyes.
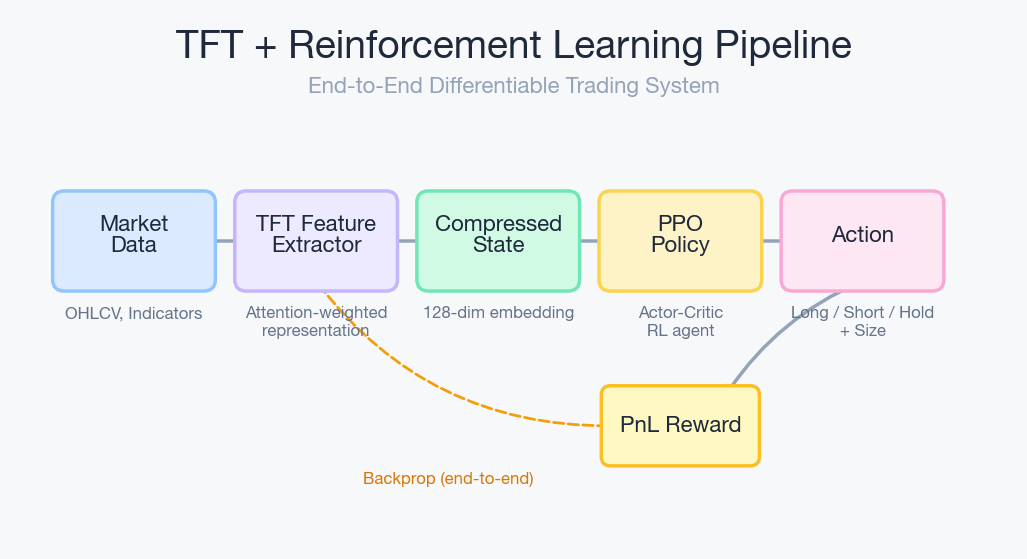
The TFT and the RL policy train end-to-end. The TFT learns to extract features that are useful for trading, not just for prediction. There's a subtle but important difference -a feature that predicts price well but has no actionable edge (because of slippage, fees, or timing) gets downweighted automatically.
What Makes This Hard
I'm not going to pretend this is straightforward. There are real challenges:
Integration with RL frameworks. Off-the-shelf TFT implementations (like PyTorch Forecasting) are built for supervised learning. Wiring them into a reinforcement learning loop with stable-baselines3 requires a custom policy network. It's not plug-and-play.
Hyperparameter sensitivity. TFT has more knobs than an LSTM -attention heads, hidden dimensions, dropout rates, LSTM layers, variable selection network size. The search space is larger.
Overfitting risk. With ~25,000 samples and a model that has attention + LSTM + gating networks, overfitting is a real concern. Careful regularization (dropout, early stopping, walk-forward validation) is non-negotiable.
Compute requirements. TFT is heavier than a pure LSTM. Training on a single RTX 3080 is doable but slower -expect 30-60 minutes per training run instead of 5-10 minutes for LSTM.
The Roadmap
Here's the honest progression I'm working through:
Phase 1 -Maximize data (current) Backfill maximum available historical data. Every extra month of data is more training signal. Also exploring multi-source data (same asset across different exchanges) to increase sample size.
Phase 2 -LSTM baseline with more data Before jumping to TFT, retrain the current LSTM models on the expanded dataset. This establishes a proper baseline. If LSTM with 3 years of data already captures most of the edge, TFT might not be worth the complexity.
Phase 3 -TFT experimentation Build the TFT as a standalone feature extractor, backtest it against the LSTM baseline using walk-forward validation. No live money until it demonstrably outperforms on out-of-sample data.
Phase 4 -TFT + RL integration If Phase 3 is promising, integrate TFT as the policy backbone in the RL agent. This is the most complex step but potentially the most rewarding.
The key principle: never add complexity unless the data justifies it. An LSTM on 3 years of data might already capture 80% of the available edge. TFT might add 10-15% improvement. Whether that's worth the engineering effort depends on scale.
Key Takeaways
- TFT is not a replacement for LSTM -it's an evolution. It literally contains an LSTM as a component, plus attention and gating mechanisms.
- Data quantity determines which architecture you should use. Under 10k samples: LSTM. 10k-25k samples: TFT. Over 50k samples: consider vanilla transformers.
- The interpretability alone might be worth the switch. Knowing why your model made a trade is invaluable for debugging and improving strategy.
- Don't optimize the model before optimizing the data. More and better data beats a fancier model every time.
- Hybrid architectures (LSTM + attention) are the pragmatic choice for retail traders with limited data and single-GPU compute.
The era of "one architecture fits all" is over. The winners in algorithmic trading will be the ones who match their model architecture to their data constraints and market structure -not the ones running the fanciest model on insufficient data.
This is part of an ongoing series documenting the journey of building RL-based trading systems. The focus is on practical implementation, not theoretical perfection.